

The DevOps Tools I'm Using Right Now (And Why)

People ask me what tools I use.
Here’s the stack, what I use them for, and why I picked them over the alternatives.
So here’s what works for managing enterprise infrastructure and keeping production running.
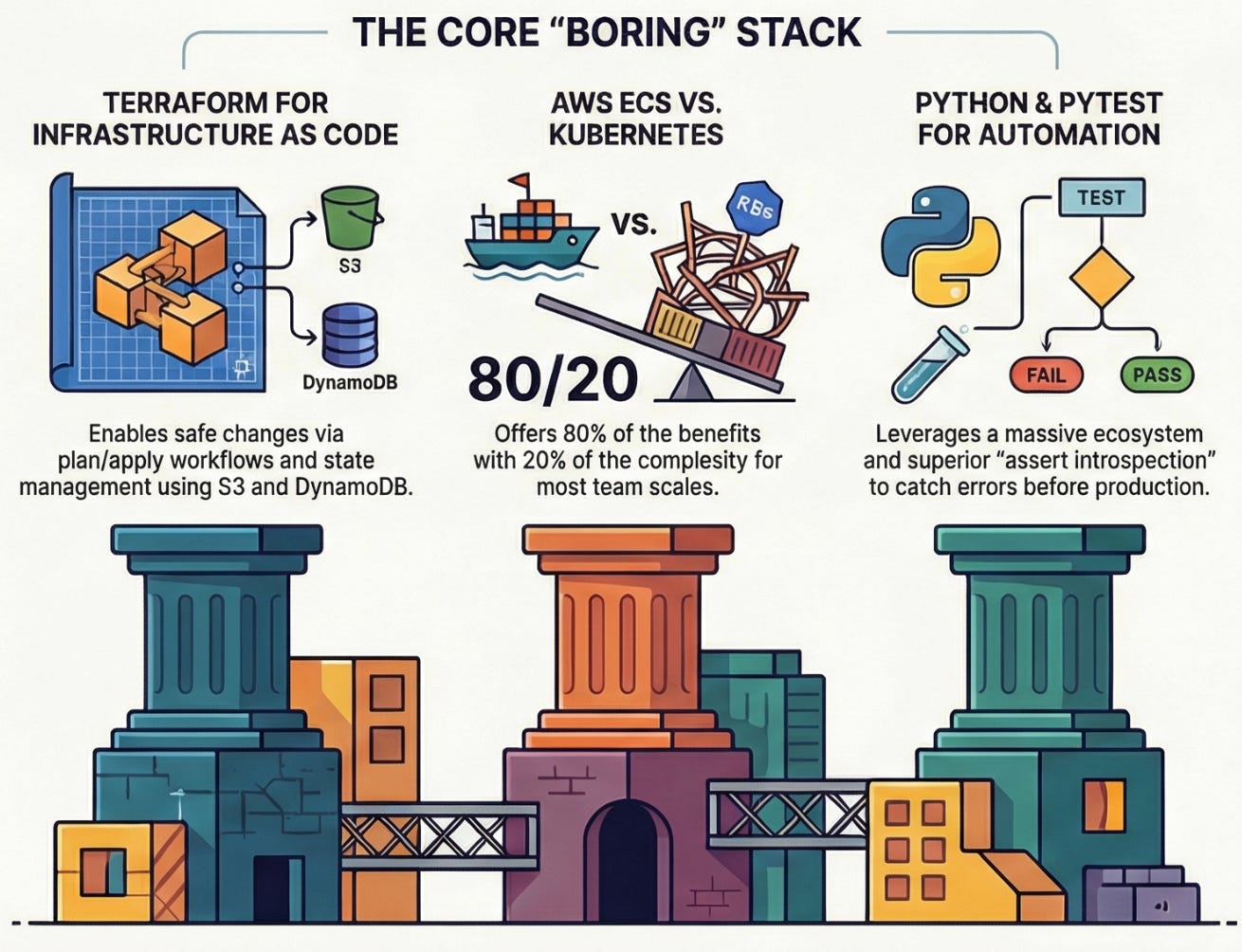
Infrastructure as Code: Terraform
What I use it for: Managing ECS task definitions, Lambda functions, cross-account permissions, basically anything that touches AWS infrastructure.
Why Terraform specifically:
State management is solid once you set it up correctly (S3 + DynamoDB for locking)
The plan/apply workflow catches mistakes before they hit production
Modules let me reuse patterns across environments without copy-paste chaos
When something breaks, I can see exactly what changed in the git diff
What I don’t use it for: Anything that changes frequently. If you’re updating a configuration every day, Terraform is overkill. That’s what environment variables and feature flags are for.
The alternative I considered: CloudFormation. Tried it, hated the YAML, never looked back. CDK is interesting but adds another language layer I don’t need.
Real talk: Terraform’s error messages are often useless. You’ll spend time Googling cryptic errors. But the plan output has saved me from breaking production enough times that it’s worth it.
Container Orchestration: AWS ECS
What I use it for: Running our microservices and the other production workloads.
Why ECS specifically:
It’s AWS-native, so IAM roles and security groups just work
Simpler than Kubernetes for our scale (we’re not Google)
Task definitions in Terraform mean infrastructure and app deployment are versioned together
The learning curve is manageable - new team members can be productive in days, not weeks
What I don’t use it for: Anything requiring super complex orchestration. If you need advanced scheduling or multi-cluster mesh networking, look at Kubernetes.
The alternative I considered: Kubernetes. We evaluated it. For our team size and use cases, ECS gave us more benefits with less complexity.
Sometimes boring technology wins.
Real talk: ECS networking can be confusing. The bridge vs awsvpc modes matter more than you’d think.
Read the docs twice.
Message Queue: RabbitMQ
What I use it for: Coordinating messages between services - specifically handling notification flows between microservices.
Why RabbitMQ specifically:
Battle-tested. It’s been around forever and the failure modes are well-documented
The management UI is actually useful for debugging
Dead letter queues saved me when consumers started failing
Clustering works when you set it up right
What I don’t use it for: Long-term message storage. If you need to replay messages from weeks ago, you want Kafka or a database, not RabbitMQ.
The alternative I considered: AWS SQS/SNS. Seriously considered it for the managed service benefits. Stuck with RabbitMQ because we already had it, it works, and migration would be risky for marginal gains.
Real talk: RabbitMQ can be finicky across multi-siloed brokers. Connection management matters. I’ve spent more time debugging connectivity issues than I’d like to admit.
Serverless: AWS Lambda
What I use it for: Disaster recovery automation - specifically distributing AWS snapshots across multiple accounts. Things that run on schedules or in response to events, not steady traffic.
Why Lambda specifically:
Zero infrastructure to maintain
Scales automatically (I don’t think about capacity)
Pay per execution means DR scripts that run once a day cost pennies
Fast to deploy - zip file, upload, done
What I don’t use it for: Long-running processes, anything with complex dependencies, or workloads where cold starts matter. Containers are better for that.
The alternative I considered: Running cron jobs on EC2. Lambda is cheaper and I don’t have to patch servers.
Real talk: Lambda limitations are real - 15 minute timeout, package size limits, cold starts. Know them before you commit.
Testing: pytest
What I use it for: Testing everything Python - integration tests for RabbitMQ message flows, validation logic, basically anything I need confidence won’t break in production.
Why pytest specifically:
Fixtures make test setup clean
The assert introspection is genuinely helpful - you see exactly what failed
Markers let me run subsets of tests (just the fast ones, just the integration tests)
It’s the standard - every Python dev knows it
What I don’t use it for: Load testing or performance testing. Wrong tool for that job.
The alternative I considered: unittest (built-in). Pytest is just better. More readable, better output, easier to write.
Real talk: Setting up good fixtures takes time upfront but pays off massively when you’re writing test #50.
Programming Language: Python
What I use it for: Everything from Lambda functions to integration tests to one-off automation scripts.
Why Python specifically:
AWS SDK (boto3) is excellent
Fast to write and iterate
Great for DevOps automation where you’re gluing services together
Huge ecosystem - if I need a library, it exists
What I don’t use it for: Performance-critical code or anything where strong typing would prevent bugs. That’s when I reach for Go or TypeScript.
The alternative I considered: Go for everything. Go is great but Python is faster to write and more people on the team can read it.
Real talk: Python 2 to 3 migrations were painful. We’re fully on 3 now but that transition was rough.
Monitoring & Alerting: CloudWatch + PagerDuty
What I use it for:
CloudWatch: Metrics, logs, alarms for AWS resources
PagerDuty: Actually getting woken up when things break
Why this combo:
CloudWatch is already there if you’re on AWS
Logs Insights is powerful enough for most queries
PagerDuty handles escalation policies and on-call rotations cleanly
What I don’t use it for: Deep application tracing. If you need distributed tracing, you want something like Datadog or New Relic.
The alternative I considered: Grafana + Prometheus. Great stack but more to maintain. For our team size, managed services win.
Real talk: CloudWatch’s query language is weird and the UI is clunky. But it’s integrated with everything and that matters more than I want to admit.
Version Control: Git + GitHub
What I use it for: Everything. Code, infrastructure, documentation, runbooks.
Why GitHub specifically:
Pull request reviews are part of our workflow
GitHub Actions for CI/CD
Everyone knows how to use it
What I don’t use it for: Large binary files. That’s what S3 is for.
The alternative I considered: GitLab. Honestly either works fine. We already had GitHub.
Real talk: I still Google git commands regularly. We all do. Don’t let anyone tell you otherwise.
The Things I Explicitly Don’t Use
Kubernetes: Too complex for our scale. ECS gives us what we need.
Ansible: Terraform handles infrastructure, Docker handles application environment. What would Ansible add?
Jenkins: GitHub Actions is simpler and lives where the code lives.
Chef/Puppet: Configuration management made sense 10 years ago. Now we use immutable infrastructure - if something needs updating, we deploy a new container.
NoSQL databases (for most things): Postgres is boring, reliable, and handles way more than people give it credit for. Don’t add complexity without a reason.
What I’m Evaluating
OpenTofu: The Terraform fork. Watching to see if the open source community moves there after the HashiCorp license change.
Dagger: CI/CD as code that runs the same locally and in CI. Interesting but not convinced yet.
Better observability: CloudWatch works but doesn’t give us the visibility we’d like. Looking at Datadog but the price is steep.
The Real Selection Criteria
How I actually choose tools:
1. Does it solve my specific problem? Not is it cool or is it popular - does it fix the thing that’s broken right now?
2. Can the team maintain it? A tool I understand and can debug at 2 AM beats a tool that’s theoretically better but nobody knows how to fix.
3. What’s the failure mode? When (not if) this breaks, can we recover? Do we understand how it fails?
4. Is it boring? Boring is good. Boring means proven. I want boring infrastructure and interesting problems to solve, not interesting infrastructure that creates problems.
5. What’s the real cost? Not just dollars - time to learn, time to maintain, on-call burden, and what happens when someone leaves.
The Stack Changes
This is what I’m using right now.
In six months it might be different. Good tools solve current problems, not theoretical future ones.
If I were starting fresh today, I’d probably use:
Terraform (still)
ECS (still, unless the team grew significantly)
Something other than RabbitMQ (maybe SQS/SNS for less operational burden)
More managed services in general
The right answer depends on your team size, your problems, and what you’re comfortable maintaining at 2 AM when things break.
What’s in your stack?
Anything I should be looking at that I’m missing?
Let me know in the comments.
With Love and DevOps,
Maxine
Related Reading:
LLMs for Humans: From Prompts to Production - My book on building production LLM systems
The DevOps Career Switch Blueprint - How to transition into DevOps without a CS degree
Last Updated: February 2026
So glad I subscribed to you!
Your real selection criteria nails it. Does it solve the problem, can you debug it at 2am, is it boring. I've been applying the same filter to local tooling. For Mac maintenance I landed on Mole, an open-source CLI that handles cleanup, uninstalls, and build artifact purging. mo purge alone cleared 10GB of forgotten node_modules. Boring shell scripts, does the job. Covered it here if you're curious: https://reading.sh/the-best-mac-cleaner-costs-nothing-and-lives-in-your-terminal-43fe1e5245e3?sk=9920cc175ebaaf5e9ef1ffd9c32b4a31