
RAG Systems Explained: From Demo to Production
A practical breakdown of how RAG works and why it gets harder outside of a demo.

The goal is to ask your internal documentation a question and get a correct answer.
No hunting through Confluence.
No Slack archaeology.
No pinging the one engineer who remembers how that service works.
That’s the promise of Retrieval-Augmented Generation, and in a demo environment, it looks like magic. You upload some PDFs, wire up an LLM, and suddenly you have a chatbot that seems to know everything about your company.
The demo always works... The production deployment is where things get interesting.
I’ve watched three different RAG implementations go from “this is going to change everything” to “why does it keep hallucinating old API endpoints” in the span of about six weeks.
The gap between demo and production isn’t a gap. It’s a canyon.
And most of the content out there about RAG systems stops right at the edge, showing you the pretty view without mentioning the climb down.
In order for that to happen, let’s understand what’s happening under the hood so that when it breaks, and it will break, you know where to look.
Hi I’m Maxine, a cloud infrastructure engineer who spends my days scaling databases, debugging production incidents, and writing about what actually works in production.
You can get a copy of my LLMs for Humans: From Prompts to Production (at 30% off right now) ←
Or for free when you become a paid subscriber.
It’s 20 chapters of practical applied AI with real production context, not theory. And it’ll help you get smarter about using AI tools in infrastructure workflows.

Checkout my work:
Plus, if you’re thinking about making a career move into cloud or DevOps and want a structured path to get there, get a copy of my The DevOps Career Switch Blueprint.
Okay, let’s get into it
The Actual Architecture
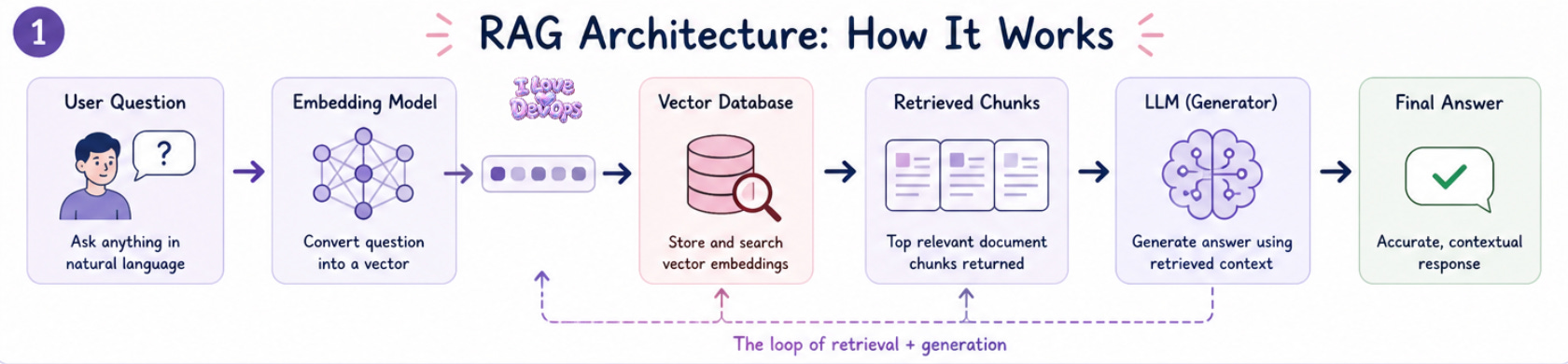
At its core, a RAG system has three components that need to work together. I’m going to walk through each one because understanding where the boundaries are is how you debug this.
Component one: the embedding pipeline. Your documents get chunked into pieces, typically 500 to 1500 tokens depending on your use case, and each chunk gets converted into a vector. That vector is a numerical representation of the semantic meaning of that text. This happens through an embedding model, something like OpenAI’s text-embedding-3-small or an open source option like bge-large-en.

The thing nobody tells you about chunking is that it’s not a set-and-forget decision.
Chunk too small and you lose context.
Chunk too large and you dilute the semantic signal.
Chunk at arbitrary boundaries and you split sentences in ways that make the embeddings meaningless.
Here’s a basic chunking config that actually works for technical documentation:
chunk_size = 1000
chunk_overlap = 200
separators = ["\n\n", "\n", ". ", " "]
That overlap is critical. Without it, you get hard edges where relevant context gets cut off, with it, you’re paying for duplicate storage and compute. Production is just tradeoffs with different price tags.
Component two: the vector store. Those embeddings need to live somewhere you can search them quickly. Pinecone, Weaviate, Qdrant, pgvector if you want to keep things in Postgres. The choice matters less than people think for most workloads, but the operational characteristics matter a lot.
Pinecone is managed and just works until you need to understand why a query is slow. Weaviate gives you more knobs but you’re running the infrastructure. Pgvector means your existing Postgres backups and monitoring cover your vector store too.
I’ve run all three in production. My current preference is Qdrant for dedicated deployments and pgvector for smaller implementations where adding another database feels like overkill.
Component three: the retrieval and generation layer. When a user asks a question, that question gets embedded using the same model as your documents. Then you do a similarity search against your vector store, typically returning the top 5 to 10 most similar chunks. Those chunks become context that gets injected into a prompt sent to your LLM.
The prompt template matters more than most teams realize:
You are a helpful assistant answering questions about internal documentation.
Use ONLY the following context to answer the question.
If the answer is not in the context, say "I don't have information about that."
Context:
{retrieved_chunks}
Question: {user_question}
Answer:
That “ONLY” and the explicit instruction about missing information are doing a lot of heavy lifting. Without them, the LLM will happily hallucinate answers that sound plausible but are completely wrong.
What Production Actually Looks Like
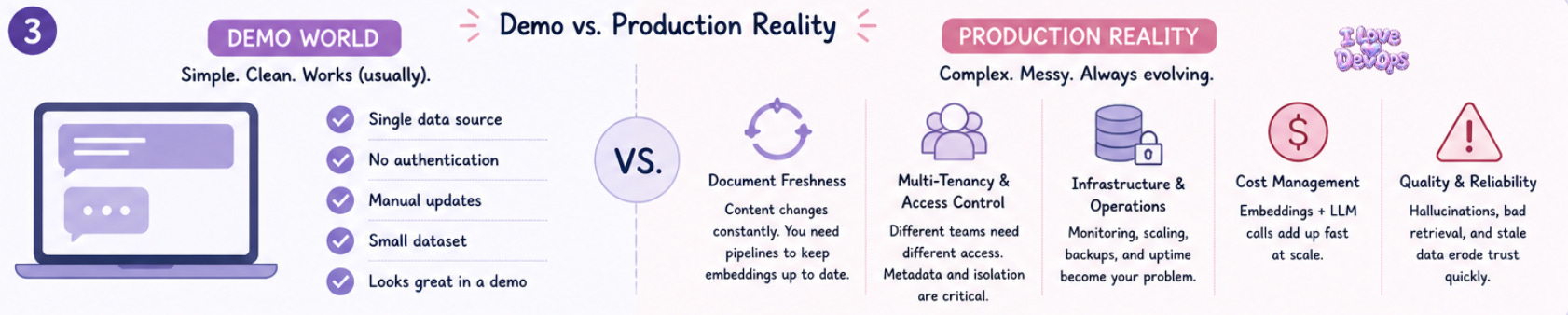
The demo version has a single collection, no auth, and queries that the developer wrote to show off the system.
Production has none of those luxuries.
Document freshness becomes your first real problem. Your Confluence space updates constantly, your runbooks change, your API documentation drifts. If your RAG system is serving stale information, it’s actively harmful, worse than having nothing at all because people trust it.
You need an ingestion pipeline that runs on a schedule or triggers on document changes. Something like:
name: rag-document-sync
schedule: "0 */4 * * *" # Every 4 hours
steps:
- fetch_changed_documents
- chunk_and_embed
- upsert_to_vector_store
- invalidate_old_embeddings
That last step is the one everyone forgets. If a document gets deleted or substantially changed, the old embeddings are now serving incorrect information. You need to track document versions and remove outdated chunks.
Multi-tenancy is the second production reality. Different teams need different document access. Your security team’s incident response playbooks shouldn’t be searchable by the marketing intern’s chatbot. This means metadata filtering on every query, namespace isolation in your vector store, and careful attention to how documents get tagged during ingestion.
Cost sneaks up on you fast. Every query is an embedding call plus an LLM call. Every document update is a batch of embedding calls. At scale, this adds up quickly.
Teams go from “this is basically free” to “$15,000 a month in API costs” in about three months of organic adoption.
Cache aggressively.
Batch your embedding calls.
Consider smaller models for embedding and retrieval even if you use a larger model for generation.
The Failure Modes of RAG Nobody Documents
Someone opens a ticket saying the RAG system gave them wrong information about the deployment process. It isn’t broken.
Not in any way your monitoring will catch.
This is the hardest part of running RAG in production. The system can be functioning perfectly, every API call succeeding, every latency metric green, and still be giving users bad answers.
Failure mode one: semantic mismatch. The user asks “how do I restart the payment service” but your documentation says “to cycle the billing microservice.” Those mean the same thing to a human. They might not retrieve the same chunks. Your embedding model learned from general text, not your company’s internal terminology.
The fix is either better documentation that uses consistent terminology, or a query expansion layer that rewrites user questions into variations before retrieval.
Failure mode two: context window stuffing. You retrieve the top 10 chunks, but 8 of them are only marginally relevant. The LLM now has to find the real answer buried in noise. Sometimes it succeeds. Sometimes it latches onto something in those irrelevant chunks and runs with it.
Fewer chunks with higher relevance thresholds often beats more chunks with lower quality. I typically start with:
top_k = 5
similarity_threshold = 0.75
If a query doesn’t get 5 results above that threshold, return fewer results. Don’t pad with garbage.
Failure mode three: the chunk boundary problem. The answer to the user’s question spans two chunks. Each chunk individually isn’t enough. Neither gets ranked highly enough to be retrieved. The user gets “I don’t have information about that” when the information absolutely exists in your corpus.
This is why chunk overlap matters. It’s also why some teams implement a two-stage retrieval where you first find relevant documents, then search within those documents more granularly.
Failure mode four: stale embeddings from model updates. You upgrade your embedding model because the new version is better. Great. Your existing embeddings were created with the old model. The semantic spaces don’t align. Queries embedded with the new model don’t retrieve correctly against old embeddings.
When you change embedding models, you have to re-embed everything. There’s no shortcut. Budget for this.
The Terraform parts that fight back
Infrastructure-as-code for RAG systems has some genuinely annoying edge cases that took me longer than I’d like to admit to figure out.
Vector store provisioning is straightforward until you need to manage collections and indexes.
Most Terraform providers for vector databases are either incomplete or community-maintained with varying levels of support.
For Qdrant on Kubernetes, try a pattern like this:
resource "helm_release" "qdrant" {
name = "qdrant"
repository = "https://qdrant.github.io/qdrant-helm"
chart = "qdrant"
version = "0.8.4"
set {
name = "replicaCount"
value = 3
}
set {
name = "persistence.size"
value = "50Gi"
}
}
But collection creation and index configuration often need to happen outside Terraform, through the API after the service is up. This breaks the “everything in code” dream. You can settle on a post-deployment script that runs through CI, which isn’t beautiful but it works.
Secrets management for API keys gets messy when you have multiple embedding providers and LLMs. I like to use a dedicated secrets path structure:
/rag-system/production/embedding-api-key
/rag-system/production/llm-api-key
/rag-system/production/vector-store-credentials
The annoyance is that these keys need to be available both to your ingestion pipeline and your query service, which might be running in different contexts with different IAM roles.
State management for embeddings is something Terraform fundamentally can’t help with. Your vector store’s contents are data, not infrastructure. You need separate tooling for tracking which documents have been embedded, which versions, with which model. Don’t try to hack this into Terraform. Don’t. Use a metadata database alongside your vector store.
Important RAG Factors
When RAG works well, the thing you notice is the absence of problems.
New engineers stop asking the same questions in Slack because they can just ask the documentation chatbot. On-call rotations get slightly less stressful because incident responders can query runbooks conversationally instead of hunting through folders. Knowledge that used to live in one person’s head becomes accessible to the whole team.
The return on investment isn’t a flashy dashboard or a dramatic demo, It’s the gradual disappearance of friction.
I think about the number of hours my teams have spent over the years searching for documentation that definitely exists somewhere. Multiply that by every engineer at a company, every week, for years. RAG doesn’t eliminate that entirely, but it meaningfully reduces it. That time goes somewhere else. Usually somewhere more valuable.
The systems themselves are more complex than the demos suggest, and the operational burden is real. But the alternative is accepting that institutional knowledge is just hard to access by default. I don’t want to accept that anymore.
What’s your experience been? Are you running RAG in production or still evaluating?
I’m particularly curious about what retrieval strategies have worked for different types of documentation. And for those who’ve tried fine-tuning embedding models, was the lift worth it?
Find me in the comments or on the socials. I want to learn from what you’ve figured out.
With Love and DevOps,
Maxine
Last Updated: May 2026

If you made it this far and you’re managing cloud infrastructure with Terraform, you might want to keep this one close too.
What Is Infrastructure as Code? A Beginner’s Guide to Terraform and Cloud Infrastructure
is where I start people who are new to IaC or who understand it conceptually but haven’t had to debug it in a real environment yet. It covers the mental model behind declarative infrastructure so that articles like this one make sense end to end, not just the code snippets.
And if you’re working with AI in your stack or trying to understand where LLMs actually fit in a production system without the hype, LLMs for Humans: From Prompts to Production is the guide I wish existed when I started. Written by an engineer for engineers, covering RAG, function calling, and the operational reality of running AI in real systems.
Sources and Further Reading
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Original RAG Paper)
Pinecone Learning Center: Chunking Strategies for RAG Applications
Good work
Noice 💎🤗