
What Is 'Platform Engineering' and Do You Actually Need It?
Everyone is building platforms. Not everyone is solving the right problem.

Your developers push code and it just works.
Builds run. Infrastructure provisions.
Deployments complete without anyone asking where the YAML file lives.
No tickets. No context switching. No three-week wait for a database.
That’s the promise, anyway.
Platform engineering has become one of those terms that shows up in every conference talk and vendor pitch deck, sitting right next to “developer experience” and “golden paths” like they’re old friends. But strip away the marketing language and you’re left with a genuine question: is this just DevOps with better branding, or is there something fundamentally different happening here?
I’ve spent the last eighteen months watching organizations attempt this transition. Some of them built something genuinely useful. Others created a new bottleneck and called it a platform team. The difference wasn’t budget or tooling or how many engineers they threw at it. The difference was whether they understood what problem they were actually solving.
In order for that to happen, let’s understand what’s happening under the hood so that when it breaks, and it will break, you know where to look.
Hi I’m Maxine, a cloud infrastructure engineer who spends my days scaling databases, debugging production incidents, and writing about what actually works in production.
You can get a copy of my LLMs for Humans: From Prompts to Production (at 30% off right now) ←
Or for free when you become a paid subscriber.
It’s 20 chapters of practical applied AI with real production context, not theory. And it’ll help you get smarter about using AI tools in infrastructure workflows.

Checkout my work:
Plus, if you’re thinking about making a career move into cloud or DevOps and want a structured path to get there, get a copy of my The DevOps Career Switch Blueprint.
Okay, let’s get into it
The Actual Definition Nobody Agrees On
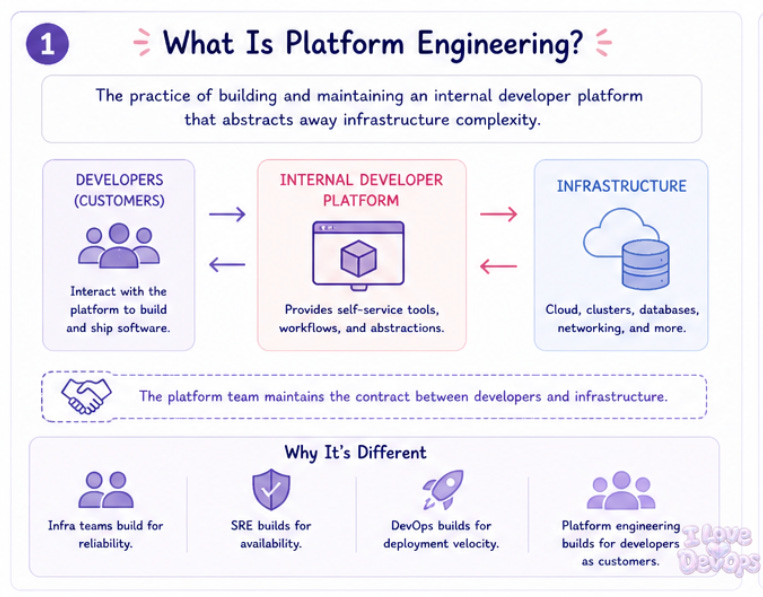
Platform engineering is the practice of building and maintaining an internal developer platform that abstracts away infrastructure complexity.
Your application teams interact with the platform.
The platform interacts with the infrastructure.
🤝 The platform team maintains the contract between those two layers.
That sounds simple. It isn’t.
The confusion starts because platform engineering overlaps significantly with what we’ve been calling DevOps, SRE, and infrastructure engineering for years. The distinction isn’t about what you’re building, it’s about who you’re building it for.
Traditional infrastructure teams build for production reliability.
SRE builds for service availability.
DevOps builds for deployment velocity.
Platform engineering builds for developers as customers.
This is a meaningful shift in orientation.
When developers are your customers, you start thinking about documentation, onboarding, self-service, and user experience. You start measuring success by whether anyone actually uses what you built, not just whether it technically works.
Infrastructure teams will deploy a beautiful Kubernetes abstraction layer with custom operators, elegant CRDs, fully automated. Only for nobody to use it. Not because it doesn’t work, but because the cognitive overhead of learning it exceeded the pain of doing things the old way. Stop building for technical elegance instead of actual adoption.
The platform will succeed. The product will fail.
Architecture: What You’re Actually Building
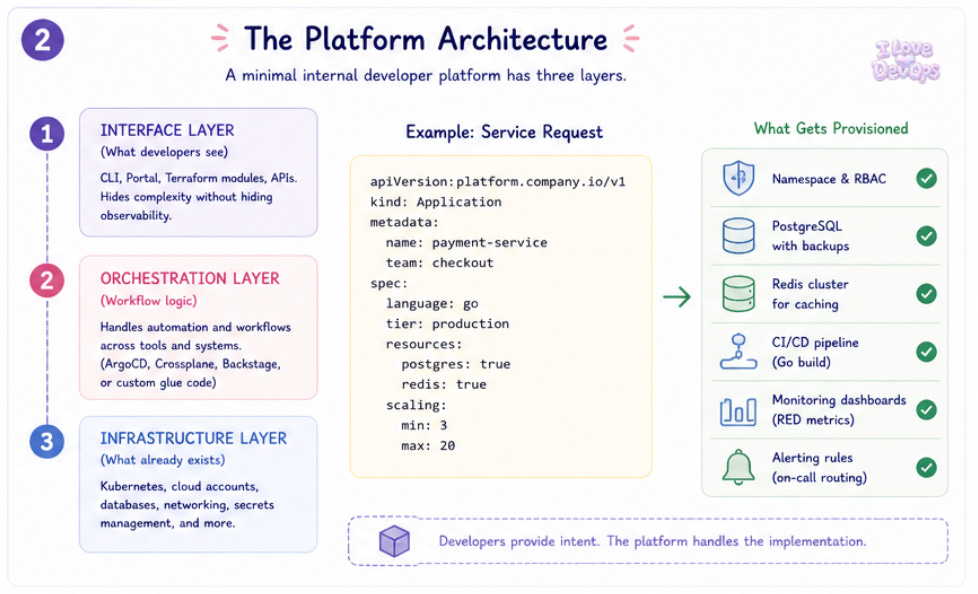
A minimal internal developer platform usually has three layers.
The interface layer (what developers see): This might be a CLI tool, a web portal, a set of Terraform modules they can reference, or a combination of all three. The key requirement is that it hides complexity without hiding observability. Developers should be able to deploy without knowing how networking works, but they should absolutely be able to see why their deployment failed.
The orchestration layer (handles the workflow logic): When a developer requests a new service, something needs to create the repository, configure the CI pipeline, provision the infrastructure, set up monitoring, and register the service in discovery. This is usually some combination of ArgoCD, Crossplane, Backstage, or custom glue code. Often a lot of custom glue code.
The infrastructure layer: Kubernetes clusters, cloud accounts, databases, networking, secrets management. Platform engineering doesn’t replace this layer, it provides a controlled interface to it.
Here’s a simplified example of what a service request might look like:
apiVersion: platform.company.io/v1
kind: Application
metadata:
name: payment-service
team: checkout
spec:
language: go
tier: production
resources:
postgres: true
redis: true
scaling:
min: 3
max: 20
From this single manifest, the platform provisions:
A namespace with appropriate RBAC
A PostgreSQL instance with backup configuration
A Redis cluster for caching
CI/CD pipelines with the correct build steps for Go
Monitoring dashboards based on RED metrics
Alerting rules routed to the checkout team’s on-call rotation
The developer didn’t specify any of that.
The platform made those decisions based on organizational defaults and the team’s context. That’s the abstraction doing its job.
Production Considerations: What Actually Hurts
Building the happy path is the easy part, but production platforms live in the exceptions.

Escape hatches matter more than golden paths. Every abstraction breaks down eventually. When a developer needs to do something your platform doesn’t support, they need a way out that doesn’t require a platform team intervention. This might mean exposing the underlying Terraform, allowing raw Kubernetes manifests alongside your custom resources, or providing a “advanced mode” that bypasses defaults.
Without escape hatches, your platform becomes a bottleneck, the whole point was to remove bottlenecks.
Versioning is harder than it looks. Your platform will change, your interfaces will evolve. You will have teams running on v1 of your abstractions while other teams have adopted v3, so supporting multiple versions simultaneously is not optional. It’s the steady state.
Platform teams break production because they treated their internal APIs with less rigor than they’d treat a customer-facing API. Your developers are customers, treat breaking changes accordingly.
Documentation debt is infrastructure debt. An undocumented platform feature doesn’t exist. A platform feature with outdated documentation is worse than one that doesn’t exist, because it teaches developers that your documentation can’t be trusted.
Budget for documentation like you budget for compute. It’s not optional.
The Failure Modes You Should Know
Someone opens a ticket saying deployments are broken. They aren’t broken.

The developer is trying to deploy a service that requires a database, but they’re using a service tier that doesn’t include database provisioning. The platform silently skipped that step because the configuration was technically valid, just not complete. Nothing failed. Nothing succeeded. The developer is staring at a pod waiting for a database connection that will never exist.
This is the most common failure pattern: valid configuration that doesn’t do what the developer expected.
Your platform will also fail when: The underlying infrastructure changes in ways your abstractions didn’t anticipate. Someone updated the Kubernetes version and now your custom admission controllers reject valid workloads.
Third-party dependencies shift behavior: Your CI provider changed their runner images and builds that worked yesterday fail today with cryptic errors.
Teams find creative workarounds that bypass your intended workflow, creating shadow infrastructure that your platform can’t manage.
The platform team gets busy with new features and stops monitoring adoption metrics. Six months later you discover that almost half of the teams have abandoned the platform entirely.
That last one is the quiet killer.
Platform engineering is a product discipline = Products die when nobody uses them.
The Terraform Edge Cases
If your platform uses Terraform under the hood, and most do, you’ll hit some specific pain points.
State management at scale is genuinely hard. When every service has its own Terraform state, you end up with thousands of state files. When you share state across services, you get locking contention and blast radius problems. There’s no clean answer. Most mature platforms end up with a hybrid approach and custom tooling to manage it.
Provider version sprawl will haunt you. Different teams adopting the platform at different times end up pinned to different provider versions. Upgrading becomes a coordination problem across dozens of workspaces. Plan for this from day one.
Here’s a pattern I’ve seen work:
module "service" {
source = "platform.company.io/modules/service"
version = "~> 3.0"
name = "payment-service"
team = "checkout"
tier = "production"
}
The module handles all the complexity, while teams only specify intent. The platform team can update module internals without requiring changes from consumers, as long as the interface stays stable.
But you’ll still end up with teams pinned to version 2.x because they customized something that doesn’t work in 3.x, and now you’re maintaining two major versions indefinitely.
This is fine. This is normal. Plan for it.
Do You Actually Need It?
Here’s my honest assessment.
You probably don’t need a platform engineering team if:
Your organization has fewer than five development teams.
Your infrastructure is relatively homogeneous.
Your deployment process, while manual, isn’t a significant bottleneck.
You don’t have dedicated infrastructure expertise to build the platform in the first place.
You probably do need it if:
Developer time waiting for infrastructure is measurable in days or weeks.
Your infrastructure team is a bottleneck for every deployment.
You have significant compliance or security requirements that need to be enforced consistently.
Teams are building their own ad-hoc solutions because the official process is too slow.
The worst outcome is building a platform that nobody asked for and nobody uses. The second worst outcome is building a platform that becomes mandatory but isn’t actually better than what it replaced.
Both happen constantly.
What Can Platform Engineering Offer
I don’t know whether platform engineering as a discipline will survive the next industry cycle, or whether it’ll get absorbed back into DevOps or SRE or whatever the next term becomes. The underlying problems are real, and the organizational structure to solve them is still evolving.
The real payoff of a good platform isn’t the features you added, it’s the problems that stopped happening.
No more tickets asking where the deployment manifest goes.
No more incidents caused by inconsistent security configurations.
No more three-person meetings to provision a staging environment.
No more knowledge locked in the head of one engineer who’s been here since 2017.
The absence of friction is invisible.
When it works, it’s quiet. The infrastructure does what it’s supposed to and the platform team works on improvements instead of firefighting.
That quiet is the success metric nobody tracks.
I’m curious if you’ve attempted platform engineering at your organization, what surprised you? Was it harder than you expected? Did developers actually use what you built, or did they find ways around it?
With Love and DevOps,
Maxine

If you made it this far and you’re managing cloud infrastructure with Terraform, you might want to keep this one close too.
What Is Infrastructure as Code? A Beginner’s Guide to Terraform and Cloud Infrastructure
is where I start people who are new to IaC or who understand it conceptually but haven’t had to debug it in a real environment yet. It covers the mental model behind declarative infrastructure so that articles like this one make sense end to end, not just the code snippets.
Last Updated: May 2026
And if you’re working with AI in your stack or trying to understand where LLMs actually fit in a production system without the hype, LLMs for Humans: From Prompts to Production is the guide I wish existed when I started. Written by an engineer for engineers, covering RAG, function calling, and the operational reality of running AI in real systems.
Sources and Further Reading
Team Topologies: Platform Teams